파이썬에서 매우 긴 리스트의 값을 처리하는데 시간이 오래 걸려서 괴로우신가요? Python에서 numba guvectorize를 사용하면 array 형태의 값 처리의 속도를 매우 빠르게 할 수 있습니다.
목차
개요: 성능 비교
우선 실행 결과를 먼저 보겠습니다. aaa는 guvectorize를 사용해서 연산한 경우이고, bbb는 그냥 python 단순 for loop을 실행한 결과입니다. 그리고 ccc는 numpy의 벡터 연산을 실시한 결과입니다.
guvectorize를 적용하면 단순 for loop를 사용했을 때에 비해 약 300배 가까이 빠른 실행을 보였습니다. 심지어 numpy의 벡터 연산을 활용하면 for loop을 사용했을 때 보다 1400배 가까이 빠르게 실행됐습니다.
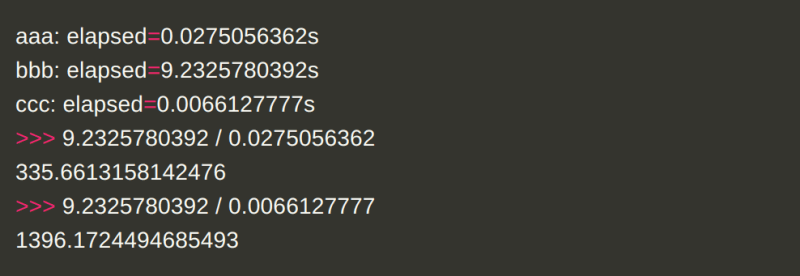
결론부터 이야기하자면, Array의 단순 연산은 numpy의 벡터연산이 가장 빠릅니다. 특정 로직에 따른 연산이 필요할 땐 guvectorize를 활용하면 됩니다.
numba guvectorize 사용방법
guvectorize의 사용법을 간단히 살펴보겠습니다. guvectorize의 경우에는 값을 return하지 않습니다. 대신에 파라미터를 넘겨주고 해당 파라미터로 값을 돌려받습니다. C의 포인터 같은 개념이지요. 따라서 파라미터로 출력값을 넘겨주어야 합니다.
@guvectorize(['void(int64[:], int64[:])'], '(n) -> (n)')
def function_name(x, y):위에 입력한 순서대로 int64[:], int64[:]는 뒤의 (n) -> (n)과 매칭됩니다. 앞의 int64[:]는 입력 값이고, 뒤의 int64[:]는 출력 값입니다.
Array가 아닌 단순 값을 파라미터로 추가하는 경우에는 아래와 같이 ()을 사용하여 처리하면 됩니다. 데이터 타입의 정의 개수와 입력, 출력 파라미터의 형식, 그리고 함수의 정의까지 모두 일치해야 합니다. 뭐 하나라도 어긋나면 에러 팍팍 뜨기 때문에 정확하게 작성하셔야 합니다.
@guvectorize(['void(int64[:], boolean, int64[:])'], '(n),() -> (n)')
def function_name(x, twist, y):guvectorize, numpy 벡터 연산 비교 소스코드
위에서 테스트 했던 소스 코드를 아래에 첨부합니다.
import time
import numpy as np
from numba import guvectorize
def timer(func):
def measure(*args, **kwargs):
begin = time.time()
val = func(*args, **kwargs)
end = time.time()
print(f">> {func.__name__}: elapsed={'%.10f' % (end - begin)}s")
return val
return measure
@timer
@guvectorize(['void(int64[:], int64[:])'], '(n) -> (n)')
def aaa(x, y):
for i, val in enumerate(x):
y[i] = val + 3 * 3 / 5 * 1.23 / 6.53
@timer
def bbb(x):
y = np.empty([len(x), 1])
for i, val in enumerate(x):
y[i] = (val + 3 * 3 / 5 * 1.23 / 6.53)
return y
@timer
def ccc(x):
return x + 3 * 3 / 5 * 1.23 / 6.53
a = np.int32(np.round(np.random.rand(5000000) * 1000))
out = aaa(a)
out = bbb(a)
out = ccc(a)참고자료
numba guvectorize 데코레이터 활용에 대한 문서를 확인하시면 도움이 되실 겁니다.