Python은 데이터 과학, 인공지능, 그리고 머신러닝 분야에서 널리 사용되는 프로그래밍 언어로, 방대한 데이터를 효율적으로 저장하고 관리할 수 있는 다양한 라이브러리를 제공합니다. 그 중에서도 HDF5(Hierarchical Data Format version 5)는 대용량 데이터를 다루는 데 매우 유용한 파일 포맷입니다. 이 글에서는 Python에서 HDF5 파일을 사용하는 방법에 대해 알아보고, 이를 통해 데이터를 효율적으로 관리하는 방법을 살펴보겠습니다.
목차
HDF5란?
HDF5는 고성능으로 대용량 데이터를 저장하고, 구조화할 수 있는 파일 포맷입니다. HDF5 파일은 다양한 데이터 유형을 저장할 수 있으며, 복잡한 데이터 구조를 계층적으로 구성할 수 있다는 장점이 있습니다. 예를 들어, HDF5 파일은 여러 개의 데이터셋(dataset)과 이를 설명하는 메타데이터(metadata)를 하나의 파일에 포함할 수 있습니다. 이러한 구조적 특성 덕분에 과학, 공학, 금융 등 데이터가 중요한 역할을 하는 여러 분야에서 널리 사용되고 있습니다.
Python에서 HDF5 사용하기
Python에서는 h5py라는 라이브러리를 통해 HDF5 파일을 쉽게 다룰 수 있습니다. h5py는 Python에서 HDF5 파일을 읽고 쓸 수 있게 해주는 인터페이스를 제공하며, NumPy 배열과도 잘 호환됩니다. 이제 h5py를 사용하여 HDF5 파일을 생성하고, 데이터를 저장하며, 다시 불러오는 과정을 살펴보겠습니다.
h5py 설치
우선, h5py 라이브러리를 설치해야 합니다. 아나콘다를 사용한다면 conda install을 사용하고, 그렇지 않다면 pip 명령어를 사용하여 간단하게 설치할 수 있습니다.
conda install h5py
# 또는
pip install h5py설치가 완료되면, Python 코드에서 h5py를 임포트하여 사용할 수 있습니다.
import h5py
import numpy as npHDF5 파일 생성 및 데이터 저장
HDF5 파일을 생성하고 데이터를 저장하는 과정은 매우 간단합니다. 아래는 NumPy 배열을 HDF5 파일에 저장하는 예제입니다.
import random
items = []
for i in range(25):
items.append(random.randint(190, 380) / 10)
data = np.array(items).reshape(5, 5)
print(data)
# HDF5 파일 생성 및 데이터 저장
with h5py.File('example.h5', 'w') as f:
dset = f.create_dataset('mydataset', data=data)위 코드에서 h5py.File 함수는 새 HDF5 파일을 생성합니다. 'w'는 쓰기 모드로 파일을 연다는 의미입니다. 그런 다음 create_dataset 메소드를 사용하여 'mydataset'이라는 이름으로 데이터를 저장합니다.
데이터셋에 메타데이터 추가하기
HDF5의 큰 장점 중 하나는 메타데이터를 추가할 수 있다는 점입니다. 메타데이터는 데이터에 대한 추가적인 정보를 제공하며, 향후 데이터를 해석하는 데 중요한 역할을 합니다.
with h5py.File('example.h5', 'w') as f:
dset = f.create_dataset('mydataset', data=data)
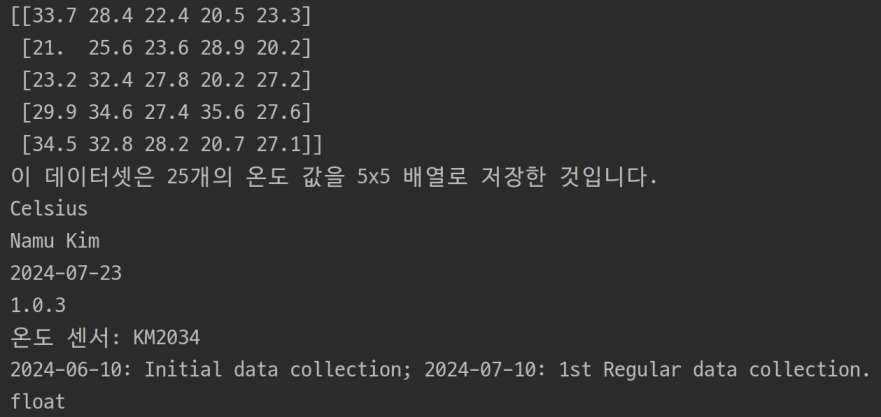
dset.attrs['description'] = '이 데이터셋은 25개의 온도 값을 5x5 배열로 저장한 것입니다.'
dset.attrs['units'] = 'Celsius'
dset.attrs['author'] = 'Namu Kim' # or creator
dset.attrs['creation_dat'] = '2024-07-23'
dset.attrs['version'] = '1.0.3'
dset.attrs['source'] = '온도 센서: KM2034'
dset.attrs['history'] = '2024-06-10: Initial data collection; 2024-07-10: 1st Regular data collection.'
dset.attrs['dtype'] = 'float'위 코드에서 attrs 속성을 사용하여 데이터셋에 메타데이터를 추가할 수 있습니다. 'description'은 메타데이터의 이름이며, ‘units’는 단위, ‘author’ 또는 ‘creator’는 데이터 셋을 생성한 사람 또는 조직, ‘version’은 데이터셋의 버전 정보, ‘source’는 데이터의 출처 또는 수집한 장비나 시스템에 대한 정보, ‘history’는 데이터셋의 주요 변경사항이나 처리과정에 대한 히스토리 기록, ‘dtype’은 데이터셋의 데이터 타입 또는 관련 설명을 할 수 있습니다. 이와 같이 여러분이 필요로하는 메타데이터를 기록하면 됩니다.
HDF5 파일에서 데이터 읽기
저장한 데이터를 다시 불러오는 것도 매우 간단합니다. 아래 예제는 저장된 데이터를 불러와서 사용하는 방법을 보여줍니다.
with h5py.File('example.h5', 'r') as f:
data = f['mydataset'][:]
description = f['mydataset'].attrs['description']
units = f['mydataset'].attrs['units']
author = f['mydataset'].attrs['author']
creation_dat = f['mydataset'].attrs['creation_dat']
version = f['mydataset'].attrs['version']
source = f['mydataset'].attrs['source']
history = f['mydataset'].attrs['history']
dtype = f['mydataset'].attrs['dtype']
print(data)
print(description)
print(units)
print(author)
print(creation_dat)
print(version)
print(source)
print(history)
print(dtype)위 코드에서 'r'은 읽기 모드로 파일을 연다는 의미입니다. 데이터셋에 접근할 때는 파일 객체에서 데이터셋 이름을 키로 사용하여 데이터를 불러올 수 있습니다. 또한, 메타데이터도 동일한 방식으로 불러올 수 있습니다.
주의할 점
HDF5 파일은 강력한 기능을 제공하지만, 몇 가지 주의할 점도 있습니다. 우선, 파일 크기가 매우 클 수 있으므로 저장 공간을 효율적으로 관리해야 합니다. 또한, 동시에 여러 프로세스에서 동일한 HDF5 파일에 접근할 경우 충돌이 발생할 수 있으므로, 병렬 처리를 위한 추가적인 조치가 필요합니다.
정리
HDF5는 대용량 데이터를 효율적으로 관리할 수 있는 강력한 파일 포맷입니다. Python에서는 h5py 라이브러리를 통해 HDF5 파일을 쉽게 생성하고, 데이터를 저장하며, 필요한 경우 다시 불러올 수 있습니다. 이 글에서는 HDF5 파일의 기본적인 사용법을 살펴보았으며, 메타데이터 추가, 그룹과 서브그룹 관리 등 실용적인 기능들을 소개했습니다. HDF5를 통해 복잡한 데이터도 체계적으로 관리하고, 효율적으로 처리할 수 있을 것입니다.