Python beautifulsoup4 사용법으로 문서의 제목을 가져오고 표의 값을 가져와 보도록 하겠습니다.
목차
Python BeautifulSoup4 개요
BeautifulSoup4는 Python에서 HTML 문서나 XML 문서를 파싱하는데 사용할 수 있습니다. PyPi에서 제공되는 현재 최신 버전은 4.12.3입니다. beautifulsoup3는 2020년도에 drop 되었다고 하니 bs4를 이용하시기 바랍니다.
문서의 제목 읽어오기
문서의 제목을 읽어오도록 하겠습니다. HTML에서 문서의 제목은 head 태그 아래의 title 태그 내에 표현합니다. title 태그는 문서 내에서 유일한 태그이므로 select_one 메서드를 사용해서 해당 태그의 값을 읽어오면 됩니다.
from bs4 import BeautifulSoup
html_string = '''
<html>
<head>
<title>나루의 HTML parsing</title>
</head>
<body>
</body>
</html>
'''
soup = BeautifulSoup(html_string, 'lxml')
title_tag = soup.select_one("head title")
print(title_tag)
print(type(title_tag))가져온 title 태그는 아래와 같이 출력됩니다. title_tag는 bs4.element.Tag의 인스턴스 객체임을 알 수 있습니다.

Tag 인스턴스 객체로부터 해당 태그 내에 있는 문자열을 가져오려면 get_text() 메서드를 사용해야 합니다.
title_tag = soup.select_one("head title")
title = title_tag.get_text()
print(title)
print(type(title))get_text() 메서드를 사용하면 그림 2와 같이 원하는 문자열을 가져올 수 있습니다. 문자열의 타입도 str인 것을 확인할 수 있습니다.

표에서 값 가져오기
이번에는 아주 간단한 표의 값을 가져와 보도록 하겠습니다. 표의 내용은 다음과 같습니다. 2개의 TR과 각 TR 별로 2개의 TD로 이루어진 표입니다.

우선 표에서 TR 태그들을 먼저 구해 오겠습니다. TR이 2개 있으므로 select_one이 아니라 select 메서드를 사용해야 합니다.
from bs4 import BeautifulSoup
html_string = '''
<html>
<head>
<title>나루의 HTML parsing</title>
</head>
<body>
<table class="main">
<tr>
<td>EPS</td>
<td>3,500</td>
</tr>
<tr>
<td>PBR</td>
<td>0.87</td>
</tr>
</table>
</body>
</html>
'''
soup = BeautifulSoup(html_string, 'lxml')
tr_tags = soup.select("table.main tr")
print(tr_tags)select 메서드를 사용하면 그림 4와 같이 List 형태로 TR Tag를 가져옵니다.
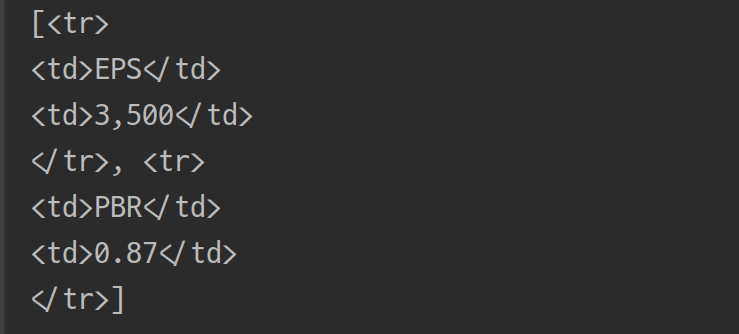
이제 TR 태그에 들어있는 TD 값을 읽어와야 합니다. for loop을 이용해서 TR Tag를 대상으로 TR 내의 TD를 가져옵니다. 그리고 첫번째 TD 값을 키 값으로 하고 두번째 TD값을 값으로 하는 딕셔너리를 만듭니다.
result = {}
for tr_tag in tr_tags:
td_tags = tr_tag.select("td")
key = td_tags[0].get_text()
value = td_tags[1].get_text()
result[key] = value
print(result)그러면 그림 5와 같이 딕셔너리로 정리된 값을 확인할 수 있습니다.

Python beautifulsoup4를 이용해서 간단히 title 태그 하나의 값을 읽어오기도 해봤고, 조금은 복잡한 표의 값을 읽어오기도 해 보았습니다. 더 복잡한 태그를 불러오는 것도 다 이 작업들의 확장일 뿐입니다.
관련 자료
PyPi의 beautifulsoup4 페이지와 beautifulsoup4 문서를 참고했습니다.